Research conducted during my time as a Ph.D. student at Durham University, UK.

Veritatem Dies Aperit - Temporally Consistent Depth Prediction Enabled by a Multi-Task Geometric and Semantic Scene Understanding Approach
Robust geometric and semantic scene understanding is ever more important in many real-world applications such as autonomous driving and robotic navigation. This work proposes a multi-task learning-based approach capable of jointly performing geometric and semantic scene understanding, namely depth prediction (monocular depth estimation and depth completion) and semantic scene segmentation. Within a single temporally constrained recurrent network, the approach uniquely takes advantage of a complex series of skip connections, adversarial training and the temporal constraint of sequential frame recurrence to produce consistent depth and semantic class labels simultaneously. The approach performs these tasks within a single model capable of two separate scene understanding objectives requiring low-level feature extraction and high-level inference, which leads to better and deeper representation learning within the model. The approach uses a feedback network that at each time step takes the output generated at the previous time step as a recurrent input. Furthermore, using a pre-trained optical flow estimation model, we ensure the temporal information is explicitly considered by the overall model during training. Additionally, as skip connections have been proven to be very effective when the input and output of a CNN share roughly similar high-level spatial features, we make use of a complex network of skip connections throughout the architecture to guarantee that no high-level spatial features are lost during training when the features are down-sampled.
Proposed Approach
The multi-task approach is made possible using the synthetic dataset of SYNTHIA, in which both ground truth depth and pixel-wise segmentation labels are available for video sequences of urban driving scenarios. Our single network takes three different inputs producing two separate outputs for the two tasks of depth prediction and semantic segmentation. The network comprises three different components: the input streams, in which the inputs are encoded, the middle stream, which fuses the features and begins the decoding process, and finally the output streams, in which the results are generated.
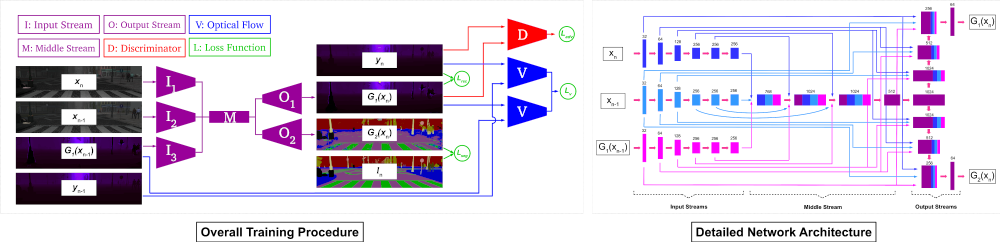
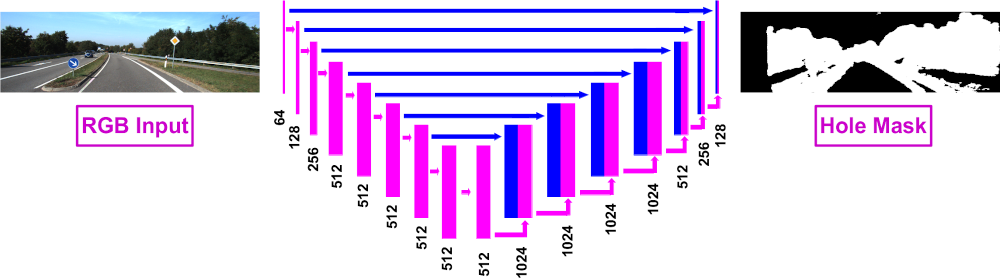
In this approach, depth prediction is considered as a supervised image-to-image translation problem, wherein an input RGB image (for depth estimation) or RGB-D image (with the depth channel containing holes for depth completion) is translated to a complete depth image. The initial solution would be to minimise the Euclidean distance between the pixel values of the output and the ground truth depth. This simple reconstruction mechanism forces the model to generate images that are structurally and contextually close to the ground truth. For depth completion, however, the process is more complex as the input is a four-channel RGB-D image with the depth containing holes that would occur during depth sensing. Since we use synthetic data from SYNTHIA, we only have access to hole-free pixel-perfect ground truth depth. While one could naively cut out random sections of the depth image to simulate holes, we opt for creating realistic and semantically meaningful holes with characteristics of those found in real-world images. A separate model is thus created and tasked with predicting where holes would be by means of pixel-wise segmentation. A number of stereo images (30,000) from the KITTI dataset are used to train the hole prediction model by calculating the disparity using Semi-Global Matching and generating a hole mask which indicates which image regions contain holes. The left RGB image is used as the input and the generated mask as the ground truth label, with cross-entropy as the loss function. When the main model is being trained to perform depth completion, the hole mask generated by the hole prediction network is employed to create the depth channel of the input RGB-D image.
Another important consideration for the approach is ensuring the depth outputs are temporally consistent. While the model is capable of implicitly learning temporal continuity when the output at each time step is recurrently used as the input at the next time step, we incorporate a light-weight pre-trained optical flow network, SPyNet, which utilises a coarse-to-fine spatial pyramid to learn residual flow at each scale, into our pipeline to explicitly enforce consistency in the presence of camera/scene motion. At each time step n, the flow between the ground truth depth frames n and n-1 is estimated using our pre-trained optical flow network as well as the flow between generated outputs from the same frames. The gradients from the optical flow network are used to train the generator to capture motion information and temporal continuity by minimising the End Point Error between the produced flows. While we utilise ground truth depth as inputs to the optical flow network, colour images can also be equally viable inputs. However, since the training data contains noisy environmental elements (e.g. lighting variations, rain, etc.), using the sharp and clean depth images leads to more desirable results. The optical flow network is pre-trained on the KITTI flow dataset. For further details of the approach, please refer to the paper.
Experimental Results
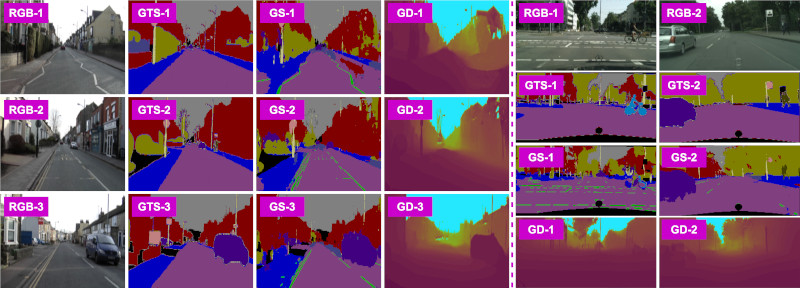
The approach is assessed using ablation studies and both qualitative and quantitative analyses using the publicly available KITTI, CamVid, Cityscapes and SYNTHIA datasets. We also utilise our own test dataset captured locally to further evaluate the approach.


Technical Implementation
All implementation is carried out using Python, PyTorch and OpenCV. All training and experiments were performed using a GeForce GTX 1080 Ti. The source code is publicly available.
Supplementary Video
For further details of the proposed approach and the results, please watch the video created as part of the supplementary material for the paper.
Publication

Paper:
DOI: 10.1109/CVPR.2019.00349
arXiv: 1903.10764
Amir Atapour-Abarghouei and Toby P. Breckon. "Veritatem Dies Aperit - Temporally Consistent Depth Prediction Enabled by a Multi-Task Geometric and Semantic Scene Understanding Approach", in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019. BibTeX
Code: PyTorch