Research conducted during my time as a Ph.D. student at Durham University, UK.

Monocular Segment-Wise Depth: Monocular Depth Estimation based on a Semantic Segmentation Prior
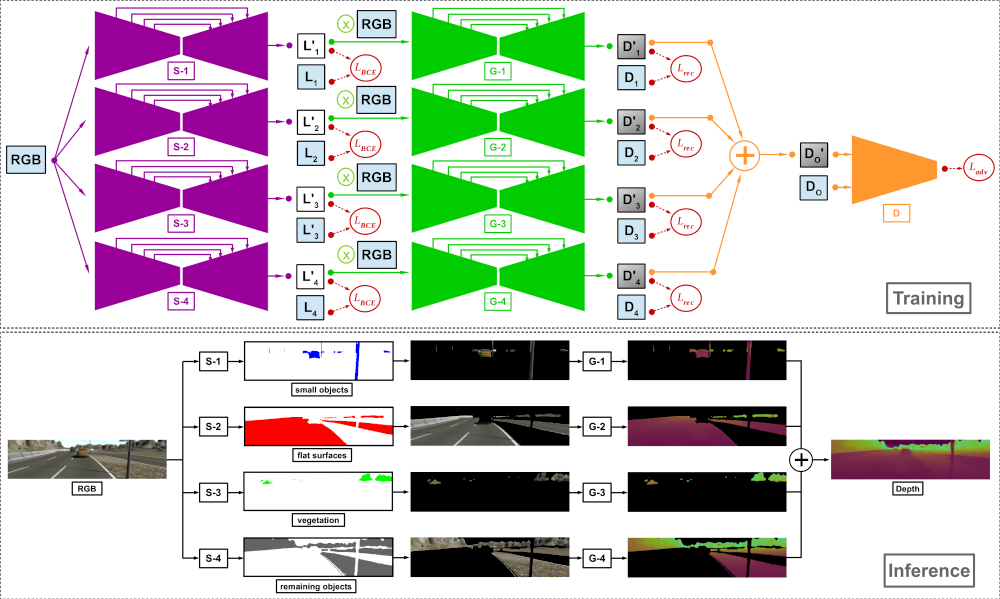
This work proposes a monocular depth estimation approach, which employs a jointly-trained pixel-wise semantic understanding step to estimate depth for individually-selected groups of objects (segments) within the scene. The separate depth outputs are efficiently fused to generate the final result. This creates more simplistic learning objectives for the jointly-trained individual networks, leading to more accurate overall depth. In this work, we propose a model that estimates scene depth based on a single RGB image by first semantically understanding the scene and then using the knowledge to generate depth for carefully selected segments, i.e. groups of scene objects. These generated segment-wise depth images are subsequently fused by means of a simple summation operation and the overall consistency is controlled by means of an adversarial training procedure as the final step. Such a training process is enabled by the use of a large-scale publicly-available dataset of synthetic images, SYNTHIA, which contains pixel-wise ground truth semantic object labels as well as pixel-perfect synthetic depth. Extensive experimentation demonstrates the efficacy of the proposed approach compared to contemporary state-of-the-art techniques within the literature.
Proposed Approach
The approach is designed to estimate depth for separate object groups that cover the entire scene when put together. Based on empirical analysis, we opt for decomposing any scene captured within an urban driving scenario into four object groups:
- small and narrow foreground objects (e.g., pedestrians, road signs, cars)
- flat surfaces (e.g., roads, buildings)
- vegetation (e.g., trees, bushes)
- background objects forming the remaining of the scene (other often unlabelled objects, e.g., a bench on the pavement).

Technical Implementation
All implementation is carried out using Python, PyTorch and OpenCV. All training and experiments were performed using a GeForce GTX 1080 Ti.
Supplementary Video
For further details of the proposed approach and the results, please watch the video created as part of the supplementary material for the paper.
Publication

Paper:
DOI: 10.1109/ICIP.2019.8803551
Citation:
Amir Atapour-Abarghouei and Toby P. Breckon. "Monocular Segment-Wise Depth: Monocular Depth Estimation based on a Semantic Segmentation Prior", in IEEE International Conference on Image Processing (ICIP), 2019.
BibTeX