Research conducted during my time as a Ph.D. student at Durham University, UK.

Real-Time Monocular Depth Estimation using Synthetic Data with Domain Adaptation via Image Style Transfer
Monocular depth estimation using learning-based approaches has become relevant and promising in recent years. Most monocular depth estimation methods, however, either need to rely on large quantities of ground truth depth data, which is extremely expensive and difficult to obtain or predict disparity as an intermediary step using a secondary supervisory signal, leading to blurring and other artefacts. Training a depth estimation model using pixel-perfect synthetic data captured from a graphically rendered virtual environment designed for gaming can resolve most of these issues, but introduces the problem of domain bias. This is the inability to apply a model trained on synthetic data to real-world scenarios. With recent advances in image style transfer and its connections with domain adaptation, this research project focuses on using style transfer and adversarial training to predict pixel perfect depth from a single real-world color image based on training over a large corpus of synthetic environment data.
Synthetic Training Data
Taking advantage of the popular highly realistic video game, Grand Theft Auto V, and an open-source plug-in, RGB and disparity images are captured from a camera view set in front of a virtual car as it automatically drives around the virtual environment and images are captured every 60 frames with randomly varying height, field of view, weather and lighting conditions at different times of day to avoid over-fitting. 80,000 images were captured with 70,000 used for training and 10,000 set aside for testing. The model trained using this synthetic data outputs a disparity image which is converted to depth using the focal length and scaled to the depth range of the KITTI image frame.
Proposed Approach
The overall depth estimation approach consists of two stages, the operations of which are carried out by two separate models, trained at the same time. The first stage includes training a depth estimation model over synthetic data captured from the game. However, as the eventual goal involves real-world images, we attempt to reduce the domain discrepancy between the synthetic data distribution and the real-world data distribution using a model trained to transfer the style of synthetic images to real-world images in the second stage.
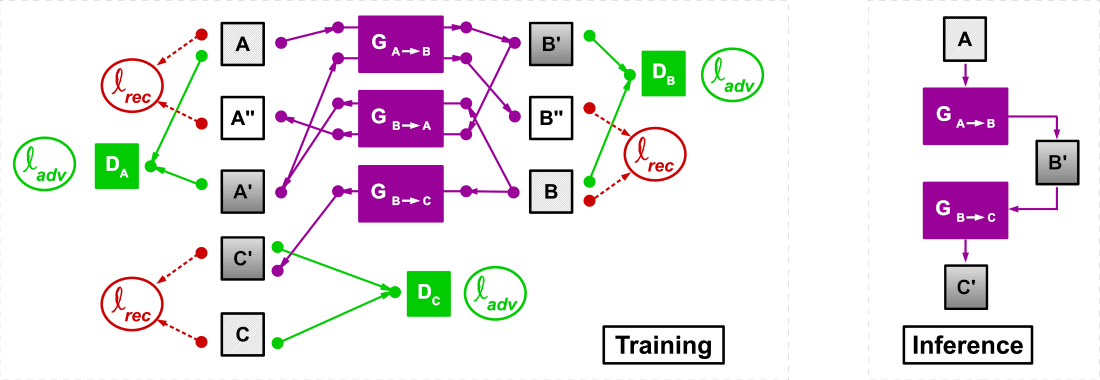
Assuming the monocular depth estimation procedure of the first stage of our approach performs well, since the model is trained on synthetic images, the idea of estimating depth from RGB images captured in the real-world is still far fetched as the synthetic and real-world images are from widely different domains. Our goal is thus to learn a mapping function from the real-world images to synthetic images such that the underlying distributions describing the data domains are identical. To accomplish this, we take advantage of CycleGAN to reduce the discrepancy between our source domain (real-world data) and our target domain (synthetic data on which our depth estimator functions). This approach uses adversarial training and cycle-consistency to translate between two sets of unaligned images from different domains.

Experimental Results
Our approach is evaluated using ablation studies and both qualitative and quantitative comparisons with state-of-the-art monocular depth estimation methods via publicly available datasets. We use KITTI for our comparisons and Make3D in addition to data captured locally at Durham, UK to test how our approach generalizes over unseen data domains. Compared to the state-of-the-art approaches tested on similar data domains, our approach generates sharper and more crisp outputs in which object boundaries and thin structures are well preserved. For further numerical and qualitative results, please refer to the paper.

Technical Implementation
All implementation is carried out using Python, PyTorch and OpenCV. All training and experiments were performed using a GeForce GTX 1080 Ti. The source code is publicly available.
Supplementary Video
For further details of the proposed approach and the results, please watch the video created as part of the supplementary material for the paper.
Publication

Paper: Citation:
Amir Atapour-Abarghouei and Toby P. Breckon. "Real-Time Monocular Depth Estimation Using Synthetic Data With Domain Adaptation via Image Style Transfer", in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. BibTeX
Code: PyTorch