Research conducted during my time as an Assistant Professor at Durham University, UK.

HINT: High-quality INpainting Transformer with Mask-Aware Encoding and Enhanced Attention
Existing image inpainting methods leverage convolution-based downsampling approaches to reduce spatial dimensions. This may result in information loss from corrupted images where the available information is inherently sparse, especially for the scenario of large missing regions. Recent advances in self-attention mechanisms within transformers have led to significant improvements in many computer vision tasks including inpainting. However, limited by the computational costs, existing methods cannot fully exploit the efficacy of long-range modelling capabilities of such models. In this paper, we propose an end-to-end High-quality INpainting Transformer, abbreviated as HINT, which consists of a novel mask-aware pixel-shuffle downsampling module (MPD) to preserve the visible information extracted from the corrupted image while maintaining the integrity of the information available for high-level inferences made within the model. Moreover, we propose a Spatially-activated Channel Attention Layer (SCAL), an efficient self-attention mechanism interpreting spatial awareness to model the corrupted image at multiple scales. To further enhance the effectiveness of SCAL, motivated by recent advanced in speech recognition, we introduce a sandwich structure that places feed-forward networks before and after the SCAL module. We demonstrate the superior performance of HINT compared to contemporary state-of-the-art models on four datasets, CelebA, CelebA-HQ, Places2, and Dunhuang.
Proposed Approach
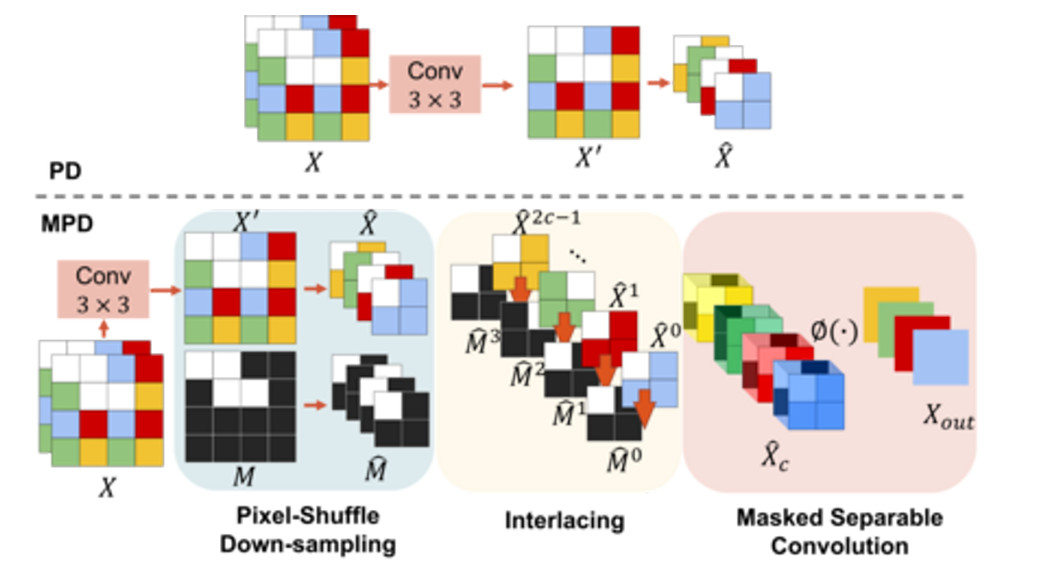
We present our transformer-based HINT approach to image inpainting, which takes advantage of our novel Mask-aware Pixel-shuffle Down-sampling (MPD) to solve the information loss issue during downsampling and further enhance the use of valid information from known areas. Within the architecture, we propose a Spatially-activated Channel Attention Layer (SCAL), which aims to handle spatial awareness while maintaining efficiency within the transformer block. The SCAL is encapsulated between two feed-forward networks, forming a sandwich-shaped transformer block, henceforth referred to as "Sandwich". This design enables the effective extraction of long-range dependencies while preserving the smooth and coherent flow of valid information through the model.
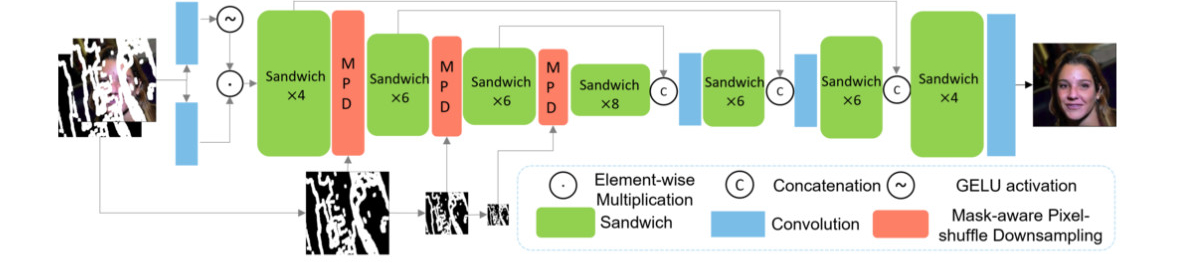
HINT consists of an end-to-end network with a gated embedding layer to selectively extract features, followed by a transformer body for modelling long-range correlations, and a projection layer to generate the output. Specifically, we insert a gating mechanism into the embedding layer serving as a feature extractor, achieved by using two parallel paths of vanilla convolutions with one path activated by a GELU non-linearity to dynamically embed the finer-grained features, leading to stronger representation learning and better optimisation.
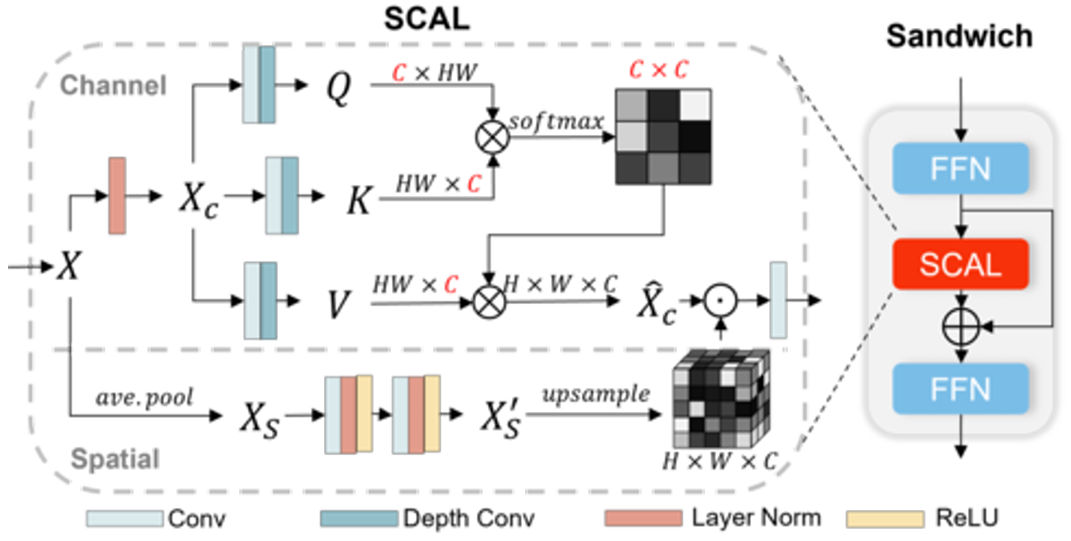
We propose a Spatially-activated Channel Attention Layer (SCAL) to strengthen the model to capture inter-channel dependencies while preserving spatial awareness. Channel self-attention is computationally viable for high-resolution features due to its linear time and memory complexity growth with channel depth. However, it fails to account for "where" the important information is across the entire spatial position, thus ignoring the relationship between feature patches. This is very important for image inpainting as the global context in the valid regions within each image can be distinct and irregularly shaped, as defined by the irregular mask. To alleviate this issue, we improve the concept of transposed attention by introducing a convolution-attention branch to capture the attention matrix of spatial locations. This enables HINT to effectively model long-range dependencies in the channel dimension, while attending to spatial locations where features should be emphasised. Unlike alternative approaches, SCAL does not increase the computational cost quadratically with input resolution, making it feasible for multi-scale context modelling.
Experimental Results
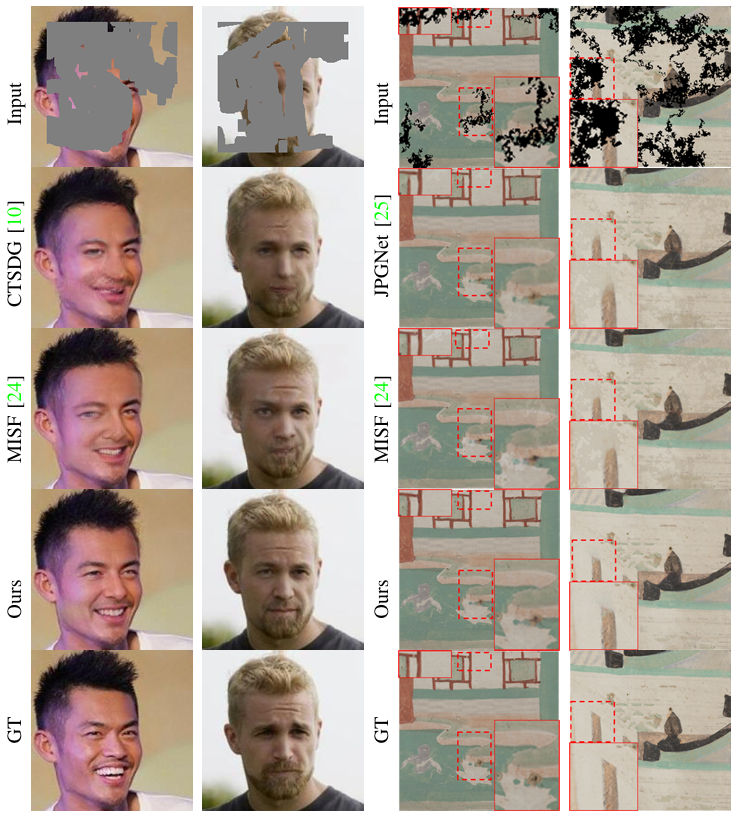
To assess the efficacy of our proposed method, we employ CelebA, CelebA-HQ, Places2-Standard and Dunhuang Challenge datasets. All experiments are conducted with 256×256 images, providing a comprehensive evaluation of our approach in a consistent and well-defined setting.

Technical Implementation
All experiments are carried out on a single NVidia A100 GPU. Our approach is more robust against small changes in the training procedure, making it more generalisable and easier to deploy. Our training pipeline does not rely on warm-up step, pre-training requirements or fine-tuning. The source code is publicly available.
Supplementary Video
For further details of the proposed approach and the results, please watch the video created as part of the supplementary material for the paper.
Publication

Paper:
DOI: 10.1109/TMM.2024.3369897
arXiv: 2402.14185
Shuang Chen, Amir Atapour-Abarghouei and Hubert P.H. Shum. "HINT: High-quality INpainting Transformer with Mask-Aware Encoding and Enhanced Attention", in IEEE Transactions on Multimedia, 2024. BibTeX
Code: PyTorch