Research conducted during my time as a Ph.D. student at Durham University, UK.

To complete or to estimate, that is the question: A Multi-Task Approach to Depth Completion and Monocular Depth Estimation
This work proposes a multi-task learning-based model capable of performing two tasks: sparse depth completion (i.e. generating complete dense scene depth given a sparse depth image as the input) and monocular depth estimation (i.e. predicting scene depth from a single RGB image) via two sub-networks jointly trained end to end using data randomly sampled from a publicly available corpus of synthetic and real-world images. The first sub-network generates a sparse depth image by learning lower level features from the scene and the second predicts a full dense depth image of the entire scene, leading to a better geometric and contextual understanding of the scene and, as a result, superior performance of the approach. The entire model can be used to infer complete scene depth from a single RGB image or the second network can be used alone to perform depth completion given a sparse depth input.
The approach is based on a mixture of publicly available synthetic training data from the Virtual KITTI dataset and naturally-sensed real-world images from the KITTI dataset. The approach specifically handles two practical depth prediction scenarios:
- Dense depth image estimation from an RGB input (monocular depth estimation).
- Sparse to dense depth completion from a sparse LiDAR (laser scanner) input (depth completion).
Proposed Approach
The approach proposed here is capable of performing monocular depth estimation and sparse depth completion using two the two publicly available datasets of KITTI and Virtual KITTI. The primary reason for using synthetic images from Virtual KITTI during training is that despite the increased depth density of the real-world imagery, depth information for the majority of the scene is still missing, leading to undesirable artefacts in regions where depth values are not available. While only using synthetic data removes the issue, due to differences in the data domains, a model only trained on synthetic data cannot be expected to perform well on real-world images without domain adaptation. Consequently, we opt for randomly sampling training images from both datasets to force the overall model to capture the underlying distribution of both data domains, and therefore, learn the full dense structure of a synthetic scene while simultaneously modelling the contextual complexity of the naturally-sensed real-world images.
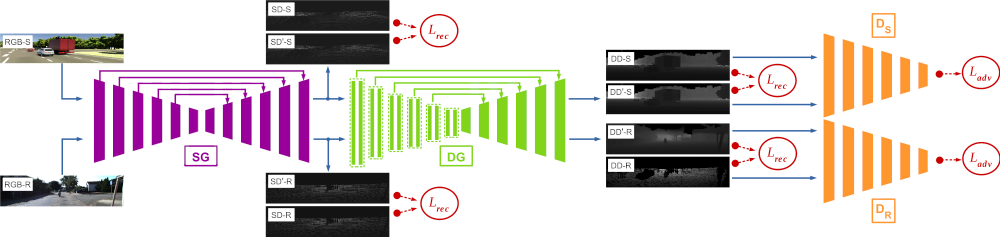
In the first stage of the approach, the sparse generator network produces its output by solving an image-to-image translation problem, in which an RGB image is translated to a sparse depth output. This can be done by minimising the Euclidean distance between the pixel values of the output and the sparse ground truth. Such a reconstruction objective encourages the model to learn the structural composition of the scene by extracting lower-level features and estimating depth in a constrained window in the scene. Since our training data is randomly sampled from synthetic and real-world images and no sparse ground truth depth is available in the synthetic dataset, it needs to be artificially created. While this could be achieved by training a separate network to predict which pixel values would exist in the sparse depth image (based on the details of the semantic scene objects such as their colour or reflectance qualities), a simpler and just as effective method would be to generate sparse synthetic depth based on a randomly selected sparse depth image from the real-world dataset.
In the second stage of the approach, the dense generator network uses the output of the sparse generator as its input and generates the dense depth image. To ensure that the overall model produces structurally and contextually sound dense depth outputs, a second reconstruction loss component is introduced to ensure the similarity of the final result to the ground truth dense depth. The issue with this loss component in the second stage arises from the use of synthetic and real-world training data together. While synthetic images are complete and without missing values (except for where necessary, e.g. sky and distant objects), real-world ground truth dense depth images from still contain large missing regions. As a result, this reconstruction loss needs to account for missing values in the real-world ground truth dense depth data. For this purpose, a binary mask is created to indicate which pixel values are missing from the ground truth dense depth. This way, the model will learn the full structure and context of the scene when the entirety of the scene is available, and at the same time, it will learn to ignore missing regions from real-world images.

Experimental Results
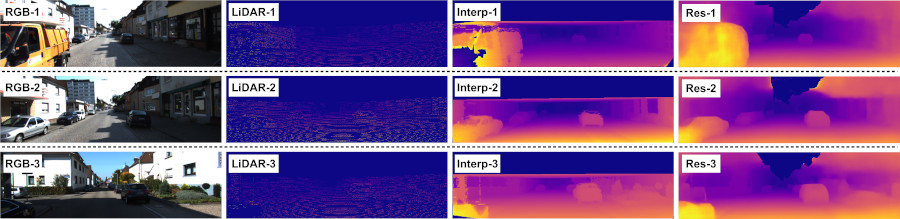
The approach is rigorously evaluated using extensive ablation studies and both qualitative and quantitative comparisons with state-of-the-art methods applied to publicly available depth completion and estimation test sets in KITTI. The generalisation capabilities of the approach are also tested using data captured locally from Durham UK. For the task of monocular depth estimation, not only is the approach capable of generating more accurate depth values for the entire scene, it does so without undesirable artefacts such as blurring or bleeding effects. Additionally, object boundaries in the results of the proposed approach are sharp and crisp, even for more distant scene components. As for sparse depth completion, due to the use of dense synthetic depth for training and improved scene representation learned by the model, the approach is capable of predicting missing depth in the entire scene. Since the upper regions of the available dense ground truth images in the depth completion training dataset of KITTI are missing, most comparators are completely incapable of predicting reasonable depth values for said regions and synthesise erroneous degenerate content. While the proposed approach is certainly not entirely immune to this issue, the use of synthetic data results in visually improved outputs. For further numerical and qualitative results, please refer to the paper.

Technical Implementation
All implementation is carried out using Python, PyTorch and OpenCV. All training and experiments were performed using a GeForce GTX 1080 Ti.
Supplementary Video
For further details of the proposed approach and the results, please watch the video created as part of the supplementary material for the paper.
Publication

Paper:
arXiv: 1908.05540
Citation:Amir Atapour-Abarghouei and Toby P. Breckon. "To Complete or to Estimate, That is the Question: A Multi-Task Approach to Depth Completion and Monocular Depth Estimation", in IEEE Conference on 3D Vision (3DV), 2019.
BibTeX